Generative language reconstruction from brain recordings
🧠 BrainLLM: Direct generative language reconstruction from brain activity
BrainLLM introduces a fully generative framework to reconstruct natural language from brain activity, particularly during continuous story listening. BrainLLM reconstructs natural language from brain recordings like fMRI using large language models (LLMs) conditioned on neural signals.
Instead of classifying among pre-generated candidates, BrainLLM:
✅ Directly injects neural activity into a large language model (LLM)
✅ Allows the LLM to freely generate words, conditioned on brain signals
✅ Supports open vocabulary generation (tens of thousands of tokens)
🧭 Visual Walkthrough
The diagram below illustrates the full BrainLLM pipeline for continous language generation:
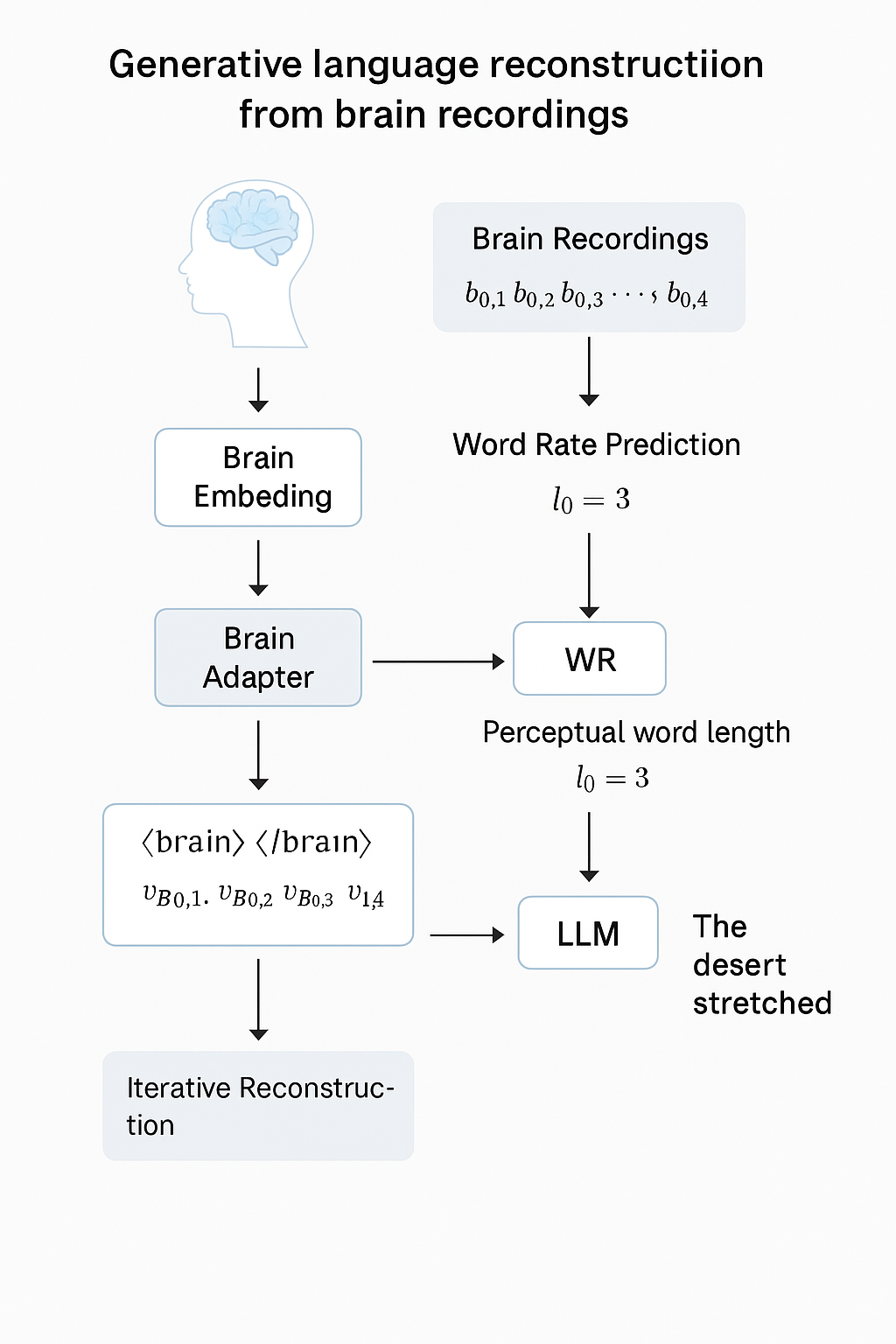
🎯 BrainLLM Objective
The model learns to predict the perceived continuation of a story based on:
- A text prompt (previous words)
- Brain signals recorded while hearing the continuation
Formally:
m̂ᵢ = F({w₁, ..., wₙ, m̂₁, ..., m̂ᵢ₋₁}, B, Θ)
Where:
- m̂ᵢ = generated token
- B = brain signals
- Θ = model parameters (brain adapter, special tokens)
Only the brain adapter and special tokens are trained—LLM weights remain frozen.
🧬 Text Embeddings and Brain Adapter
- Text tokens transformed by LLM’s embedding layer to VW ∈ ℝⁿˣᵈ
- Brain signals (fMRI) projected to same space using a non-linear brain adapter
Adapter process:
vBᵢ = MLP(bᵢ + pᵢ)
- pᵢ = position embedding (captures temporal order)
- MLP = multi-layer perceptron with ReLU activations
- Final brain embedding dimension matches LLM embedding size
Unified Input:
[⟨brain⟩, vB₁, ..., vBₜ, ⟨/brain⟩, vW₁, ..., vWₙ]
🧪 Evaluation Settings
Two modes:
✅ Continuation Generation:
- Predict next tokens with ground-truth prompt + brain signals
✅ Full-Text Reconstruction:
- Only brain signals provided per window
- Autoregressive generation using prior outputs as prompt
Performance evaluated using:
- BLEU, ROUGE, METEOR, WER (machine metrics)
- Human evaluations of fluency and similarity
🏗️ Pipeline Overview
- Record brain activity during story listening
- Process brain signals into LLM-friendly embeddings
- Predict perceived word timing with a Word Rate Model
- Autoregressively generate text using LLM + brain signals
- Repeat for continuous full-text reconstruction
⚙️ Step-by-Step Example
Scenario:
-
Participant listens to:
“The desert stretched endlessly before him. The wind whispered softly across the dunes.” -
Brain data:
- TR = 2 seconds
- 10,000 voxels per scan
- 3737 total TRs
Step 1: Brain Recordings
b₀,₁, b₀,₂, b₀,₃, b₀,₄ ∈ ℝ¹⁰⁰⁰⁰
Step 2: Brain Embedding
vB₀,₁, vB₀,₂, vB₀,₃, vB₀,₄ ∈ ℝᵈ
Step 3: Word Rate Prediction
l₀ = WR(b₀,₁, b₀,₂, b₀,₃, b₀,₄) = 3
Step 4: LLM Text Generation
[⟨brain⟩, vB₀,₁, vB₀,₂, vB₀,₃, vB₀,₄, ⟨/brain⟩]
Generates:
["The", "desert", "stretched"]
Step 5: Iterative Reconstruction
Next window:
l₁ = WR(b₁,₁, ..., b₁,₄) = 4
LLM input:
[⟨brain⟩, vB₁,₁, ..., vB₁,₄, ⟨/brain⟩, "The", "desert", "stretched"]
LLM generates:
["endlessly", "before", "him", "."]
Repeat for full text.
🧩 Pseudocode for BrainLLM Full-Text Decoding
for each time frame k:
brain_signals = [bₖ,₁, bₖ,₂, bₖ,₃, bₖ,₄]
lₖ = WordRateModel(brain_signals)
brain_embs = [BrainAdapter(b) for b in brain_signals]
input_seq = [<brain>] + brain_embs + [</brain>] + previous_tokens
new_tokens = LLM.generate(input_seq, num_tokens=lₖ)
previous_tokens.extend(new_tokens)
🎯 Why BrainLLM Works
✅ Aligns brain signals to LLM embedding space
✅ Uses future brain signals to handle BOLD delay
✅ Keeps LLM frozen, only trains adapter and special tokens
✅ Supports flexible, natural language reconstruction