Instruction-Tuned Video-Audio MLLMs for Brain Alignment
Abstract
Recent voxel-wise multimodal brain encoding studies have shown that multimodal large language models (MLLMs) exhibit a higher degree of brain alignment compared to unimodal models in both unimodal and multimodal stimulus settings. More recently, instruction-tuned multimodal models have shown to generate task-specific representations that align strongly with brain activity. However, prior work evaluating the brain alignment of MLLMs has primarily focused on unimodal settings or relied on non-instruction-tuned multimodal models for multimodal stimuli. To address this gap, we investigated brain alignment, that is, measuring the degree of predictivity of neural activity recorded while participants were watching naturalistic movies (video along with audio) with representations derived from MLLMs. We utilized instruction-specific embeddings from six video and two audio instruction-tuned MLLMs. Experiments with 13 video task-specific instructions show that instruction-tuned video MLLMs significantly outperform non-instruction-tuned multimodal (by ~15%) and unimodal models (by ~20%). Our evaluation of MLLMs for both video and audio tasks using language-guided instructions shows clear disentanglement in task-specific representations from MLLMs, leading to precise differentiation of multimodal functional processing in the brain. We also find that MLLM layers align hierarchically with the brain, with early sensory areas showing strong alignment with early layers, while higher-level visual and language regions align more with middle to late layers. These findings provide clear evidence for the role of task-specific instructions in improving the alignment between brain activity and MLLMs, and open new avenues for mapping joint information processing in both the systems.
Why Instruction-Tuned MLLMs?
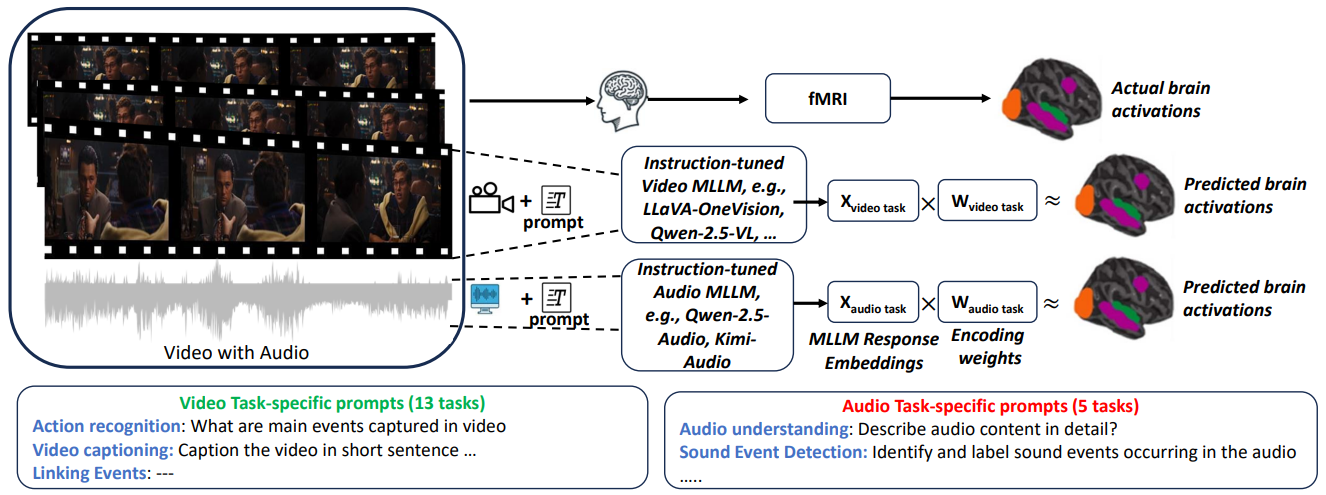
Instruction-tuned multimodal large language models (MLLMs) have shown remarkable ability to follow complex instructions across different modalities. Our research demonstrates that these models can provide insights into functional specialization in the brain when processing multimodal stimuli like videos with audio. Unlike previous approaches that used non-instruction-tuned models, our method leverages task-specific instructions to better capture the nuanced processing that occurs in different brain regions.
Key Contributions
🔬 First Brain-MLLM Alignment Study
We are the first to align instruction-tuned video and audio MLLMs with brain activity during naturalistic movie viewing, providing new insights into multimodal processing in the brain.
🎥 Task-Specific Representations
Our approach demonstrates that task-specific instructions lead to clear disentanglement in MLLM representations, which better align with functional specialization in the brain.
🧠 Hierarchical Alignment
We show that MLLM layers align hierarchically with brain regions, with early layers matching sensory areas and later layers matching higher-level processing regions.
Results
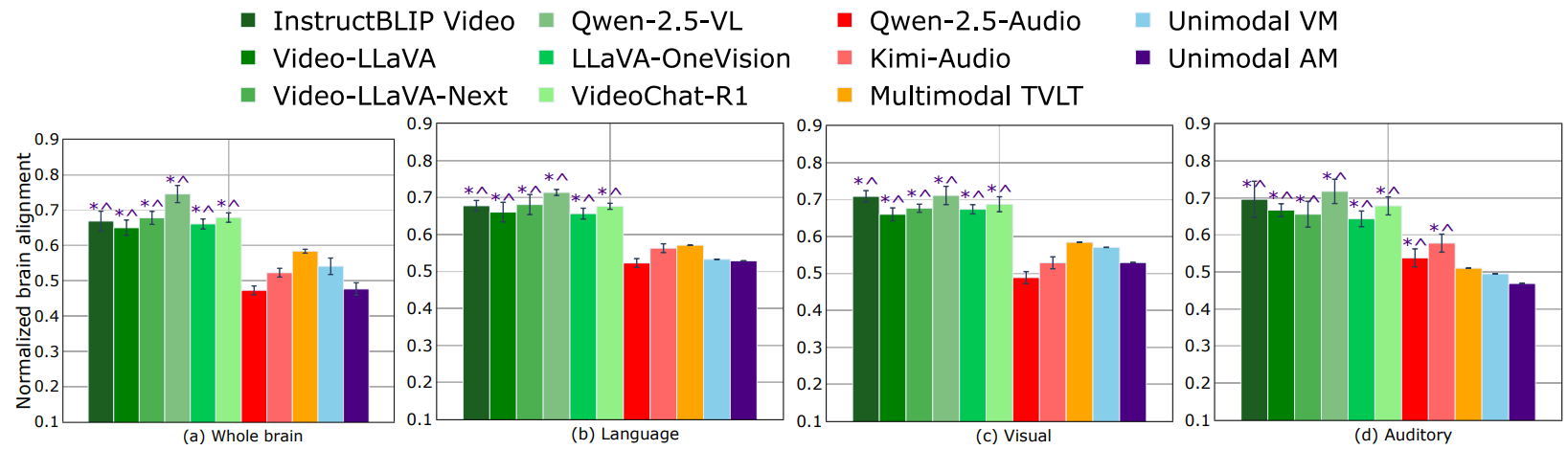
Our experiments demonstrate that instruction-tuned video MLLMs significantly outperform non-instruction-tuned multimodal models by approximately 15% and unimodal models by around 20% in brain alignment tasks. This performance gain is consistent across different brain regions and for various task-specific instructions.
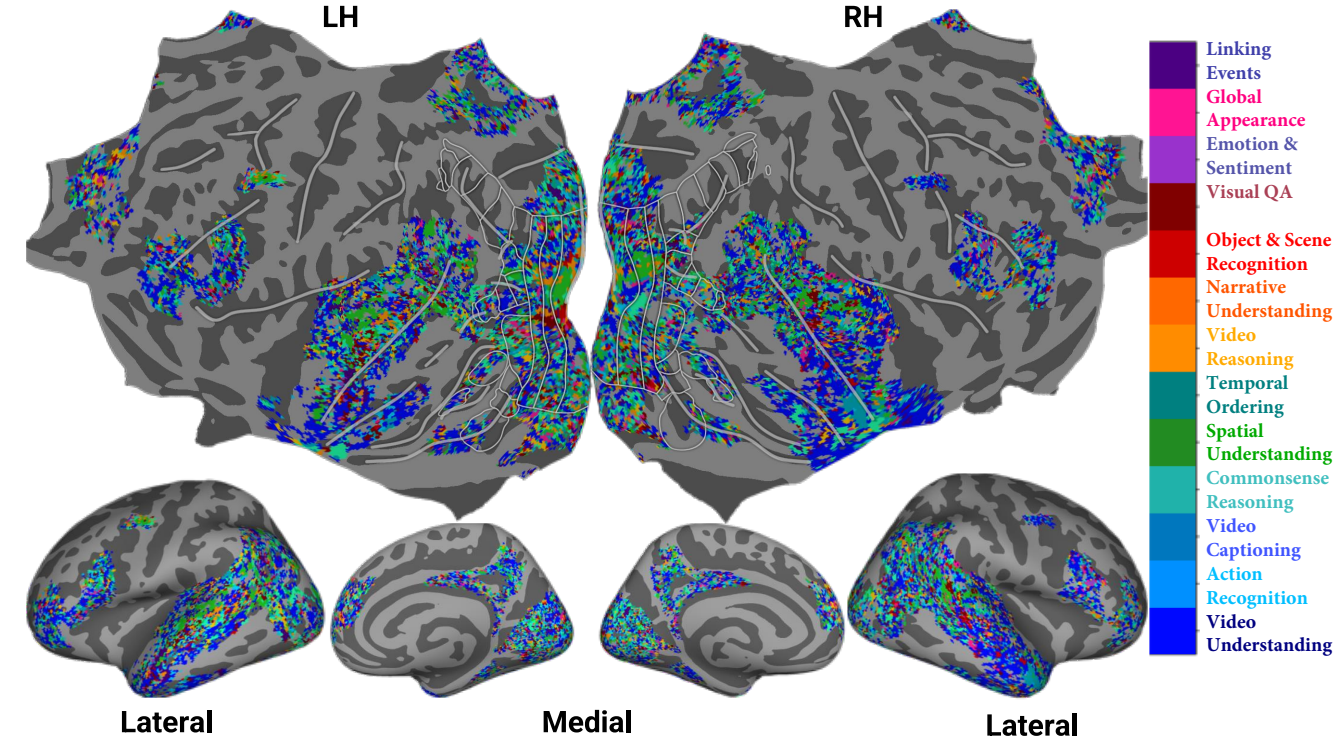
The Figure above illustrates the consistent performance advantage of instruction-tuned MLLMs across different brain regions. The task-specific nature of these models allows them to better capture the nuanced processing that occurs in different functional areas of the brain.
Key Findings
- Instruction-tuned video MLLMs outperform non-instruction-tuned models by ~15% on average
- Performance gains are most pronounced in higher-level visual and language processing regions
- Using task-specific instructions leads to better disentanglement of functional specialization
- Layer-wise analysis shows hierarchical alignment between model layers and brain regions
Methodology
We use Neuromod Movie10 fMRI data from participants while they watched naturalistic movie clips with audio. We then extracted embeddings from different layers of six video and two audio instruction-tuned MLLMs using 13 different task-specific instructions. These embeddings were used to predict brain activity in various regions, and the prediction performance was compared with non-instruction-tuned models and unimodal models.
Data Collection
Participants viewed naturalistic movie clips while undergoing fMRI scanning. The stimuli included diverse content spanning different genres, emotions, and semantic content to capture a wide range of brain responses.
Model Selection
We utilized six instruction-tuned video MLLMs (including VideoChat-R1, Qwen-2.5-VL, Video-LLaVA, LLaVA-OneVision, LLaVA-Next-Video, InstructBLIPVideo) and two instruction-tuned audio MLLMs (Qwen-2.5-Audio, Kimi-Audio). For comparison, we also included non-instruction-tuned multimodal models and unimodal models.
Task-Specific Instructions
We generated 13 different task-specific instructions for the video models, including:
- Describe the visual content in detail
- Identify all objects and their interactions
- Analyze the emotional tone of the scene
- Describe the temporal sequence of events
- Explain the spatial relationships between objects
- And 8 more task-specific instructions
Brain Alignment Analysis
We computed the correlation between model embeddings and brain activity using ridge regression with cross-validation. The alignment was measured in terms of prediction accuracy across different brain regions. We also performed layer-wise analysis to understand the hierarchical relationship between model layers and brain regions.
Citation
BibTeX
@article{oota2025instruction,
title={Instruction-Tuned Video-Audio Models Elucidate Functional Specialization in the Brain},
author={Oota, Subba Reddy and Pahwa, Khushbu and Jindal, Prachi and Namburi, Satyasai Srinath and Singh, Maneesh and Chakraborty, Tanmoy and Bapi, Raju S and Gupta, Manish},
journal={arXiv preprint arXiv:2506.08277},
year={2025}
}